
세브리움
Cerebrium
복잡한 서버 설정 없이 고성능 GPU 인프라에 AI 모델을 즉시 배포하고 자동 확장하는 서버리스 플랫폼
검증된 사실
- 최근 변경
- 2026-03-08 Cerebrium은 컨테이너 이미지 배포 방식을 재설계하여 콜드 스타트를 최대 75% 단축하는 지연 로딩(lazy-loading) 기술을 공식 블로그를 통해 발표했습니다. 소스: https://w
2026-06-20 직접 확인 · 자동 검증 데이터
제품 화면
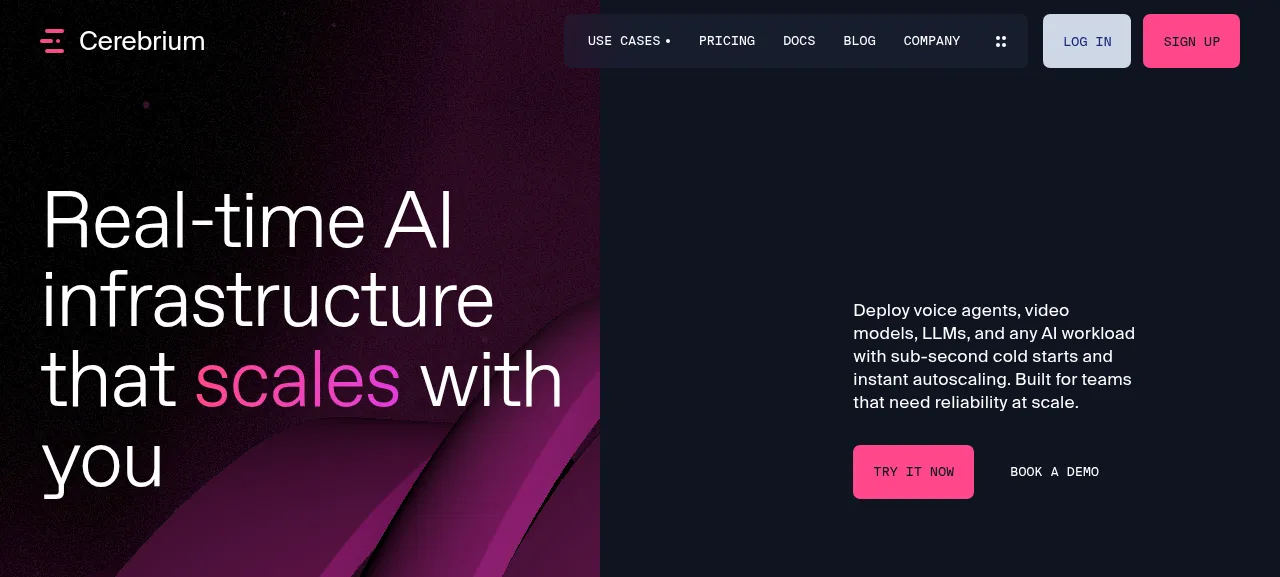
2026-06-20 확인
가격 정보
무료 티어 $30 크레딧 제공. Standard 플랜 $100/월 + 컴퓨트 비용. GPU·CPU·메모리 초당 분리 과금 (예: 중간급 GPU 구성 약 $1.36/시간 수준). 콜드 스타트 시간 과금 제외.
최근 업데이트와 소식
- 투자Cerebrium, 시드 850만 달러 유치
서버리스 GPU AI 인프라 플랫폼 Cerebrium이 2026년 초 Gradient 주도로 시드 850만 달러를 유치했습니다. Tavus·Deepgram·Vapi 등이 사용 중입니다.
근거: [APPROX_DATE] Cerebrium은 2026년 초 Gradient 주도로 시드 850만 달러를 유치했다고 발표했습니다.
소개AI 요약
활용 워크플로우
입력
세브리움
출력
실시간 음성 AI 워크플로우
PipeCat 프레임워크와 Deepgram/Cartesia를 연동하여 500ms 미만의 지연 시간을 가진 음성 에이전트 구축
고성능 LLM 최적화 경로
vLLM, SGLang 또는 TensorRT-LLM을 활용하여 H100/H200 GPU에서 추론 처리량 극대화
샌드박스 코드 실행 환경
E2B 등과 연동하여 AI 에이전트가 생성한 코드를 격리된 환경에서 즉시 실행 및 배포
핵심 차별점: 업계 최고 수준의 2~4초 콜드 스타트와 초당 과금 체계를 결합하여, 실시간 AI 에이전트 배포에 최적화된 고성능 GPU 인프라를 제공합니다.
주요 기능AI 요약
- 2~4초 초고속 콜드 스타트 (과금 제외)
- T4부터 H100·H200까지 12종 이상 GPU 선택
- 초당 GPU·CPU·메모리 분리 과금 구조
- 다중 리전 글로벌 라우팅 및 자동 스케일링
- 실시간 음성·비디오 AI 최적화 (PipeCat 연동)
- 지속성 볼륨 스토리지 및 커스텀 런타임 지원
장점 & 단점AI 분석
공식 정보와 공개 피드백을 함께 정리한 참고 메모입니다
장점
- 머신러닝 설정 및 유지보수의 복잡성을 제거하는 서버리스 인프라를 제공합니다.
- 단 한 줄의 코드로 주요 ML 프레임워크의 모델을 쉽게 배포할 수 있습니다.
- 5초 미만의 빠른 콜드 스타트 시간으로 즉각적인 응답이 가능합니다.
- 추론 시간에만 비용이 청구되어 유휴 GPU 시간에 대한 비용이 발생하지 않아 비용 효율적입니다.
- 0에서 수천 개의 요청까지 자동으로 스케일링하여 트래픽 급증에 대응합니다.
- H100, A100 등 10가지 이상의 다양한 GPU 유형을 지원하여 모델 요구사항에 맞는 하드웨어 선택이 가능합니다.
단점
- 기존 프로그래밍 방식에 비해 AI 도구 사용 시 제어력이 제한될 수 있습니다.
- 대량의 데이터를 처리할 때 어려움이 발생할 수 있습니다.
- 대규모 프로젝트의 경우 여전히 확장성 문제가 있을 수 있다는 우려가 있습니다.
- 수요에 따라 리소스 가용성에 제한이 있을 수 있습니다.
활용 사례AI 요약
- 500ms 미만 지연 시간의 실시간 음성 AI 에이전트 구축
- 트래픽 변동이 심한 AI 서비스의 비용 효율적 운영
- H100·H200 GPU를 활용한 대규모 LLM 서버리스 배포
- 글로벌 사용자를 위한 다중 리전 추론 엔드포인트 구성
사용자 리뷰
리뷰를 불러오는 중...
대안 도구
이 도구 대신 사용할 수 있는 대안
클로바 AI
Naver
한국어와 국내 맥락에 최적화된 하이퍼클로바 X로 AI 서비스를 개발·배포하는 통합 플랫폼
애스크코디
코드 생성부터 테스트, 문서화까지 개발 전 과정을 지원하는 멀티 모델 기반 AI 코딩 어시스턴트
컨티뉴
IDE 안에서 원하는 LLM을 선택해 코드 맥락을 제어하는 오픈소스 AI 코딩 어시스턴트
세레브라스
세계 최대 크기의 AI 전용 칩으로 기존 GPU보다 수십 배 빠른 초고속 LLM 추론 환경을 제공하는 API 플랫폼
블랙박스 AI
여러 AI 모델을 골라 쓰고 2억 개 이상의 저장소를 검색하며 실시간 자동완성까지 제공하는 AI 코딩 어시스턴트
그록
자체 LPU 칩으로 오픈소스 모델을 빠르게 돌리는 추론 전용 클라우드 플랫폼입니다. GPU 기반 서비스보다 초당 토큰 생성량이 높고 첫 응답까지의 지연이 짧은 점이 핵심입니다.