
캑터스
Cactus
모바일 기기에서 데이터 유출 없이 고성능 AI 모델을 로컬로 구동하는 오픈 소스 SDK
검증된 사실
- 라이브 가격
- Free · 무료2026-06-15 확인
- GitHub
- ★ 4,245
- 최근 변경
- 2026-05-12 Cactus가 26M 파라미터 함수 호출 전용 오픈소스 모델 Needle을 공개하였으며, INT4 양자화 시 14MB로 소비자 기기에서 초당 1,200 토큰 디코딩 속도를 달성합니다. 소스: ht
2026-06-15 직접 확인 · 자동 검증 데이터
제품 화면
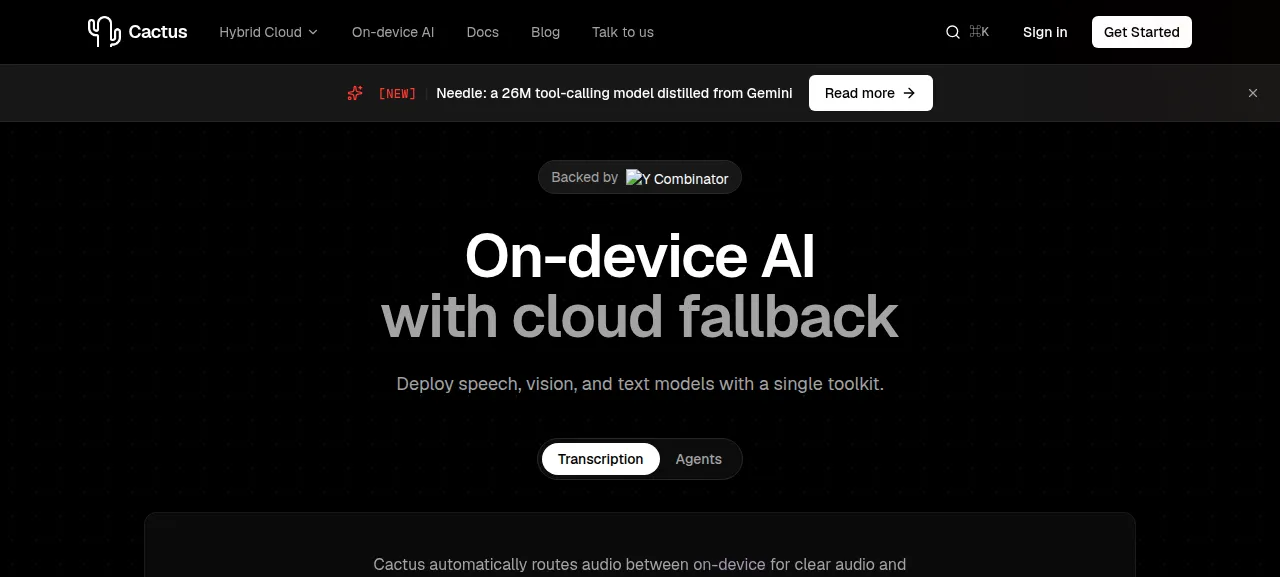
2026-06-15 확인
가격 정보
기본적인 온디바이스 추론 기능을 제공하는 무료 티어가 존재한다. 하이브리드 클라우드 추론, 맞춤형 모델, 하드웨어 가속 등 고급 기능은 유료로 제공된다. 구체적인 유료 플랜의 월 고정 가격은 공개되어 있지 않으며 사용량이나 요구 사항에 따라 달라질 수 있다.
최근 업데이트와 소식
- 버전 업데이트Cactus 출시 — 스마트폰·웨어러블 로컬 AI 추론 엔진
Cactus Compute가 2026년 2월 9일 스마트폰·웨어러블·저전력 기기용 크로스플랫폼 오픈소스 추론 프레임워크 Cactus를 출시했습니다. HuggingFace의 모든 LLM·VLM과 GGUF 모델을 지원하며 Flutter·React-Native로 제공됩니다.
근거: Fondo: 'Cactus Launches: Deploy AI Models Locally on Smartphones' — launched February 9, 2026
소개AI 요약
활용 워크플로우
입력
캑터스
출력
시각적 에이전트 설계
에이전트 빌더 캔버스를 통해 복잡한 AI 워크플로우를 코딩 없이 시각적으로 구성하고 배포
로컬 프라이버시 모드
네트워크 연결 없이 모든 데이터를 기기 내에서만 처리하여 제로 트러스트 보안 환경 구축
멀티모달 통합 추론
텍스트, 비전, 음성 모델을 동시에 로컬에서 구동하여 하이브리드 인터랙션 구현
핵심 차별점: 모바일 하드웨어 전용 커널 최적화로 50ms 미만의 지연 시간을 보장하는 온디바이스 멀티모달 AI SDK
주요 기능AI 요약
- Apple NPU·Qualcomm·MediaTek 하드웨어 가속으로 50ms 미만 TTFT 달성
- iOS·Android·macOS 단일 SDK 크로스플랫폼 지원
- 도구 호출(Tool Calling) 및 음성 전사 기능 내장
- 온디바이스↔클라우드 하이브리드 라우팅으로 복잡도에 따라 자동 전환
- Flutter·React Native·Kotlin Multiplatform 네이티브 SDK 지원
- GGUF 포맷 지원으로 Llama·Qwen·Mistral 등 주요 모델 즉시 활용
장점 & 단점AI 분석
공식 정보와 공개 피드백을 함께 정리한 참고 메모입니다
장점
- 24시간 운영되는 AI 콜센터로 비즈니스 시간 외에도 전화 응대 가능
- 고객 확인 및 예약 프로세스를 자동화하여 운영 효율성 증대
- 검증 문서를 몇 분 만에 언더라이팅 모델로 전환하여 업무 시간 단축
- 시장 비교 및 임료율 데이터 기반의 신뢰도 높은 분석 제공
활용 사례AI 요약
- 금융·의료용 보안 온디바이스 AI 챗봇 구현
- 실시간 오프라인 음성 전사 및 번역 앱 개발
- 기기 내 로컬 이미지·비디오 분석 에이전트 구축
- 저지연 게임 내 AI 캐릭터 상호작용 개발
- 인터넷 미연결 환경에서의 엣지 AI 솔루션 구축
사용자 리뷰
리뷰를 불러오는 중...
대안 도구
이 도구 대신 사용할 수 있는 대안
클로바 AI
Naver
한국어와 국내 맥락에 최적화된 하이퍼클로바 X로 AI 서비스를 개발·배포하는 통합 플랫폼
애스크코디
코드 생성부터 테스트, 문서화까지 개발 전 과정을 지원하는 멀티 모델 기반 AI 코딩 어시스턴트
컨티뉴
IDE 안에서 원하는 LLM을 선택해 코드 맥락을 제어하는 오픈소스 AI 코딩 어시스턴트
세레브라스
세계 최대 크기의 AI 전용 칩으로 기존 GPU보다 수십 배 빠른 초고속 LLM 추론 환경을 제공하는 API 플랫폼
블랙박스 AI
여러 AI 모델을 골라 쓰고 2억 개 이상의 저장소를 검색하며 실시간 자동완성까지 제공하는 AI 코딩 어시스턴트
그록
자체 LPU 칩으로 오픈소스 모델을 빠르게 돌리는 추론 전용 클라우드 플랫폼입니다. GPU 기반 서비스보다 초당 토큰 생성량이 높고 첫 응답까지의 지연이 짧은 점이 핵심입니다.