
트레이니
Trainy
Trainy는 대규모 GPU 워크로드를 온디맨드로 실행하고 관리하기 위한 ML 인프라 플랫폼입니다.
검증된 사실
- 라이브 가격
- Free · 무료2026-06-20 확인
- 최근 변경
- YC 지원 및 Applied Digital 투자 유치(Pre-Seed). Konduktor AI 에이전트 스킬 오픈소스 공개. 소스: https://github.com/Trainy-ai/konduktor-skills
2026-06-20 직접 확인 · 자동 검증 데이터
제품 화면
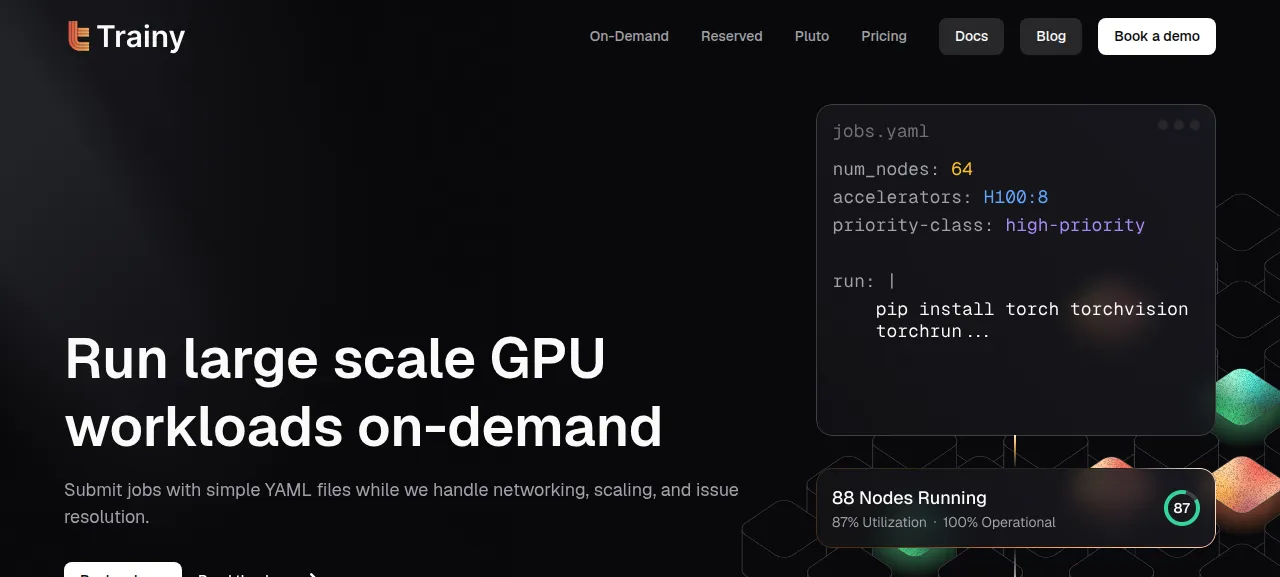
2026-06-20 확인
가격 정보
AI 모델 학습을 위한 GPU 클러스터 관리 및 오케스트레이션 플랫폼입니다. 복잡한 쿠버네티스 환경에서의 작업 제출을 간소화하고 GPU 자원 할당을 최적화하는 기능을 제공합니다. 요금은 GPU 사용 시간당 과금되며, 최저 $3.60/GPU hour부터 시작합니다.
최근 업데이트와 소식
- 투자YC 지원 및 Applied Digital 투자 유치(Pre-Seed). Konduktor AI 에이전트 스킬 오픈소스 공개.
YC 지원 및 Applied Digital 투자 유치(Pre-Seed). Konduktor AI 에이전트 스킬 오픈소스 공개.
소개AI 요약
활용 워크플로우
입력
트레이니
출력
자동 장애 복구 워크플로우
MLOps 엔지니어가 스팟 인스턴스 중단이나 노드 결함 발생 시, 작업을 자동 저장하고 새로운 노드에서 즉시 재개하도록 설정
인터랙티브 개발 환경(Dev Box)
AI 연구원이 복잡한 설정 없이 YAML 실행만으로 고사양 GPU가 포함된 Jupyter 또는 VS Code 개발 환경을 즉시 생성
멀티 클라우드 비용 최적화
스타트업 CTO가 여러 클라우드 공급자의 GPU 가격을 비교하고 가장 저렴한 가용 자원을 선택하여 학습 비용을 최대 70% 절감
핵심 차별점: 기존 Slurm의 복잡성 없이 YAML 하나로 멀티 클라우드 GPU 클러스터를 오케스트레이션하고 하드웨어 결함을 실시간으로 감지/차단하는 ML 전용 인프라 솔루션
주요 기능AI 요약
- Konduktor 스케줄러 기반 우선순위 큐 관리
- 멀티 클라우드 GPU 배포(코드 변경 없음)
- 학습 전 GPU 하드웨어 무결성 자동 검증
- 노드 장애 자동 감지 및 복구
- 실시간 GPU 사용량·비용 모니터링 대시보드
- 온디맨드 + 예약 클러스터 하이브리드 과금
활용 사례AI 요약
- LLM 대규모 분산 사전학습 및 파인튜닝
- 안정적인 장기 학습 작업(체크포인트 자동 관리)
- 멀티 클라우드 GPU 자원 통합 스케줄링
- 스팟 인스턴스 활용 비용 최적화 학습
사용자 리뷰
리뷰를 불러오는 중...
대안 도구
이 도구 대신 사용할 수 있는 대안
클로바 AI
Naver
한국어와 국내 맥락에 최적화된 하이퍼클로바 X로 AI 서비스를 개발·배포하는 통합 플랫폼
애스크코디
코드 생성부터 테스트, 문서화까지 개발 전 과정을 지원하는 멀티 모델 기반 AI 코딩 어시스턴트
컨티뉴
IDE 안에서 원하는 LLM을 선택해 코드 맥락을 제어하는 오픈소스 AI 코딩 어시스턴트
세레브라스
세계 최대 크기의 AI 전용 칩으로 기존 GPU보다 수십 배 빠른 초고속 LLM 추론 환경을 제공하는 API 플랫폼
블랙박스 AI
여러 AI 모델을 골라 쓰고 2억 개 이상의 저장소를 검색하며 실시간 자동완성까지 제공하는 AI 코딩 어시스턴트
그록
자체 LPU 칩으로 오픈소스 모델을 빠르게 돌리는 추론 전용 클라우드 플랫폼입니다. GPU 기반 서비스보다 초당 토큰 생성량이 높고 첫 응답까지의 지연이 짧은 점이 핵심입니다.