
웹하운드
Webhound
자연어 지시만으로 웹 전체를 탐색해 구조화된 데이터셋과 출처 인용 리서치 보고서를 자동 생성하는 AI 에이전트
검증된 사실
- 라이브 가격
- Free · 무료2026-06-20 확인
- 최근 변경
- 2026-04-28 Webhound가 채팅 중심 인터페이스에서 다시 작성(composer) 중심 홈 화면으로 전환했습니다. 소스: https://www.webhound.ai/news 2026-04-23 Webhoun
2026-06-20 직접 확인 · 자동 검증 데이터
제품 화면
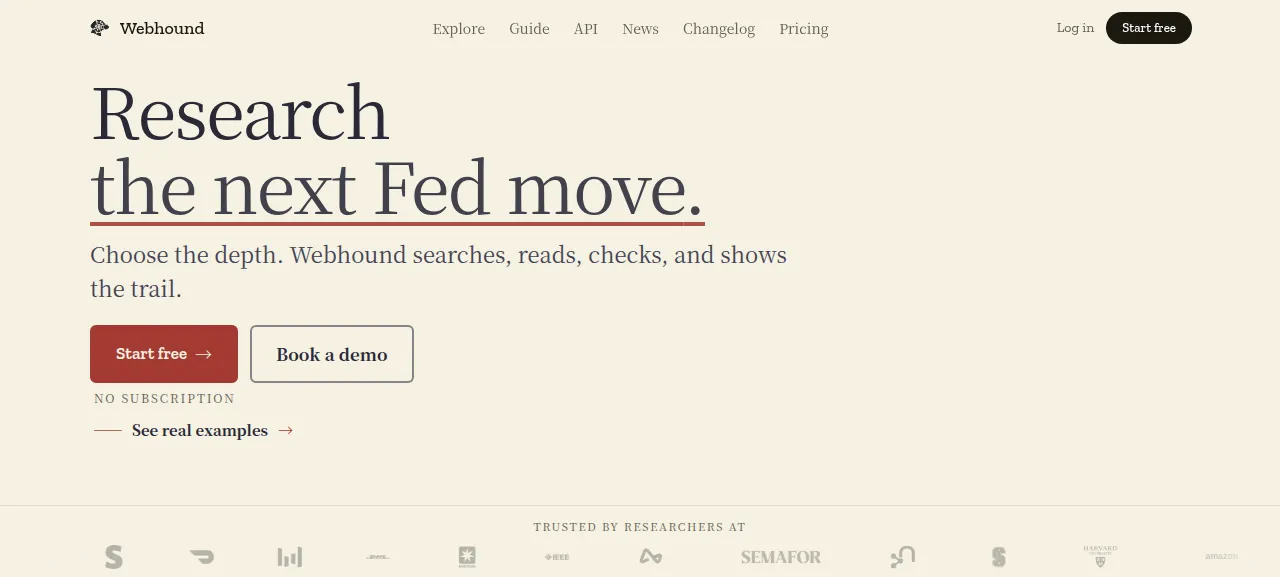
2026-06-20 확인
가격 정보
웹 리서치 및 데이터 추출을 위한 AI 에이전트로, 2025년 11월부터 구독료 없는 '사용량 기반 결제(Pay-As-You-Go)' 모델로 전환되었습니다. 신규 가입 시 $5의 무료 크레딧을 제공하며, 이후에는 구글 검색($0.0015), 페이지 방문($0.0025) 등 작업 단위별로 비용이 청구됩니다. 별도의 월간 구독료 없이 실제 사용한 만큼만 지불하면 됩니다.
최근 업데이트와 소식
- 버전 업데이트2026년 1월 30일, 예산 기반 심층 리서치 에이전트 'Webhound Reports'를 출시하였습니다. 모든 주장에 원본 소스 링크와 도구 호출 내역이 포함...
2026년 1월 30일, 예산 기반 심층 리서치 에이전트 'Webhound Reports'를 출시하였습니다. 모든 주장에 원본 소스 링크와 도구 호출 내역이 포함된 감사 추적을 제공합니다.
- 소식Webhound가 채팅 중심 인터페이스에서 다시 작성(composer) 중심 홈 화면으로 전환했습니다.
Webhound가 채팅 중심 인터페이스에서 다시 작성(composer) 중심 홈 화면으로 전환했습니다.
- 소식Webhound 리서치 기능에 LaTeX 수식 렌더링 지원과 DOI 룩업 폴백 기능이 추가되었습니다.
Webhound 리서치 기능에 LaTeX 수식 렌더링 지원과 DOI 룩업 폴백 기능이 추가되었습니다.
소개AI 요약
활용 워크플로우
핵심 차별점: 멀티 에이전트가 스스로 탐색 계획을 세우고 페이지를 마크다운으로 변환하여 처리함으로써, 코딩 없이도 복잡한 웹 구조에서 고순도 데이터셋을 구축하는 자율형 리서치 능력
주요 기능AI 요약
- 병렬 멀티 에이전트 시스템(검색·비평·검증 에이전트 협업)
- 자연어 지시 기반 자동 웹 스크래핑 및 데이터 구조화
- 모든 결과에 원본 소스 링크 포함된 감사 추적
- CSV·Excel·JSON 클린 데이터 내보내기
- 중복 방지 Long-term Memory 및 스케줄링 기반 업데이트
- 구독 없는 종량제(Pay-as-you-go) 요금 모델
장점 & 단점AI 분석
공식 정보와 공개 피드백을 함께 정리한 참고 메모입니다
장점
- 수동 작업 없이 구조화된 데이터 세트 생성 및 내보내기
- 경쟁사 가격 및 기능 추적 기능
- 검색 기반 데이터 세트 생성으로 데이터 관련성 및 정확성 보장
- 복잡한 구성이나 워크플로를 피하는 간단한 프롬프트 인터페이스
- 예산에 따라 연구 품질을 조정할 수 있는 기능
- 모든 결과에 대한 출처 및 링크 제공으로 신뢰성 확보
단점
- 대규모 데이터 세트의 경우 에이전트 컨텍스트가 최대 1000-5000행에서 중단될 수 있음
- 대규모 데이터 세트 처리를 위한 더 나은 아키텍처 작업 중
- 초기 쿼리 및 처리량이 많을 수 있으며, 공개적으로 사용 가능한 데이터의 일부만 발견될 수 있음
- 데이터 추출에 시간이 오래 걸릴 수 있음
활용 사례AI 요약
- 경쟁사 가격 및 기능 변경 이력 추적
- 특정 산업군 잠재 고객 리드 및 연락처 대량 생성
- 시장 트렌드 분석을 위한 심층 리서치 보고서 작성
- ML 모델 학습용 도메인 특화 데이터셋 구축
- 투자 리서치 및 기업 정보 자동 수집
사용자 리뷰
리뷰를 불러오는 중...
대안 도구
이 도구 대신 사용할 수 있는 대안
팔란티르
방대한 데이터를 통합해 기업과 정부의 실질적인 의사결정을 지원하는 AI 운영 플랫폼
던 앤 브래드스트리트
전 세계 6억 개 이상의 기업 정보를 D-U-N-S 번호로 식별해 신용·공급망 리스크를 점검하는 B2B 데이터 플랫폼입니다. ChatD&B 같은 생성형 AI와 ChatGPT·Copilot·Claude 연동으로 데이터를 자연어와 워크플로에서 바로 끌어 씁니다.
데이터스트림즈
개인정보 규정을 준수하며 복잡한 데이터 수집과 전송 과정을 로우코드로 통합 관리하는 오케스트레이션 플랫폼
타블로 AI
자연어 질문으로 복잡한 시각화 대시보드를 생성하고 비즈니스 핵심 지표의 변화를 실시간으로 탐지하는 지능형 분석 도구
데이터브릭스
데이터 레이크와 웨어하우스를 통합해 기업용 AI 모델 개발부터 데이터 분석까지 원스톱으로 지원하는 플랫폼
세코다
데이터 카탈로그·계보·거버넌스를 AI로 통합 관리하며 자연어 질문으로 전사 데이터를 탐색하는 플랫폼 (Atlassian 인수)