
틴포일
Tinfoil
NVIDIA 기밀 컴퓨팅을 활용해 클라우드에서도 온프레미스 수준의 보안으로 AI를 실행하는 플랫폼
검증된 사실
- GitHub
- ★ 1,157
- 최근 변경
- 2026-06-16 Tinfoil Chat에 대화 기록 시맨틱 검색 및 크로스-채팅 메모리 기능을 프라이버시를 유지하며 구현하기 위한 인프라 기반 작업 계획을 공개하였습니다. 소스: https://tinfoil.sh
2026-06-15 직접 확인 · 자동 검증 데이터
제품 화면
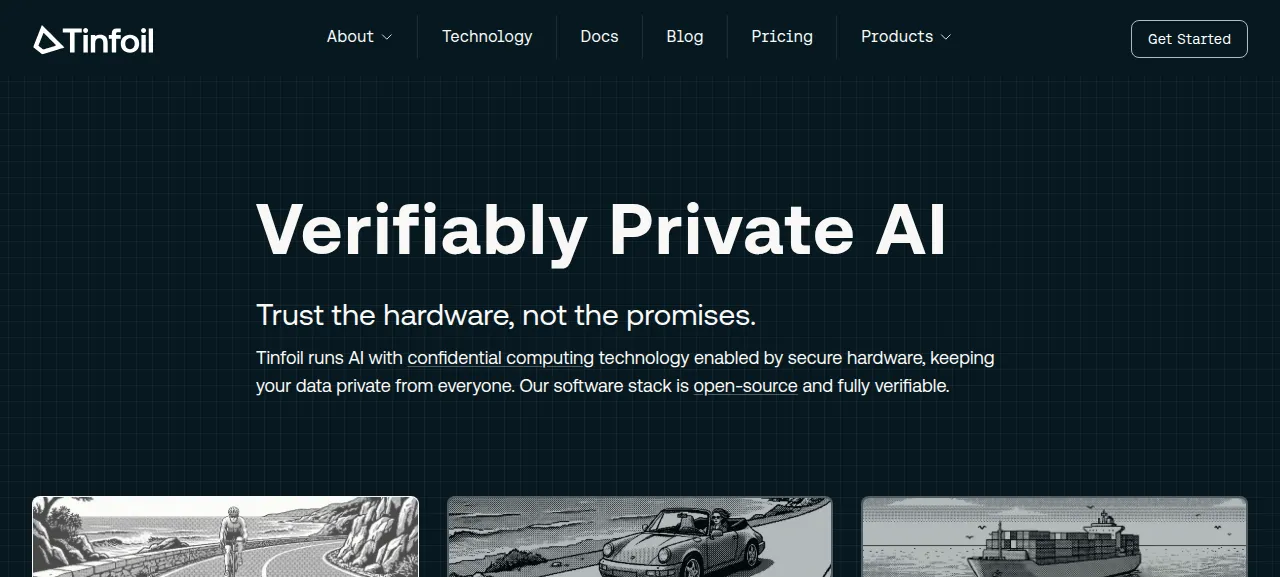
2026-06-15 확인
가격 정보
개인용 Private Chat은 고정 월 요금으로 제공되며, 개발자용 Private Inference는 사용량 기반(Pay-as-you-go)으로 과금됩니다. 무료 티어는 제공되지 않으며, 스타트업 및 엔터프라이즈 플랜은 보안 요구 사항에 따라 별도 견적이 책정됩니다. 하드웨어 기반의 보안 엔클레이브를 통해 데이터 프라이버시를 보장하는 것이 특징입니다.
최근 업데이트와 소식
- 소식Tinfoil Chat에 대화 기록 시맨틱 검색 및 크로스-채팅 메모리 기능을 프라이버시를 유지하며 구현하기 위한 인프라 기반 작업 계획을 공개하였습니다.
Tinfoil Chat에 대화 기록 시맨틱 검색 및 크로스-채팅 메모리 기능을 프라이버시를 유지하며 구현하기 위한 인프라 기반 작업 계획을 공개하였습니다.
- 버전 업데이트Pour Demain이 Tinfoil Containers를 활용해 744B 파라미터 모델의 가중치를 공개하지 않고 기밀 엔클레이브 내에서 해석 가능성 평가를 수행...
Pour Demain이 Tinfoil Containers를 활용해 744B 파라미터 모델의 가중치를 공개하지 않고 기밀 엔클레이브 내에서 해석 가능성 평가를 수행한 사례가 공개되었습니다.
- 성능 측정384K 토큰 컨텍스트 윈도우를 지원하며 에이전틱 엔지니어링 및 코딩 벤치마크에 최적화된 GLM-5.2 모델이 Tinfoil 플랫폼에 추가되었습니다.
384K 토큰 컨텍스트 윈도우를 지원하며 에이전틱 엔지니어링 및 코딩 벤치마크에 최적화된 GLM-5.2 모델이 Tinfoil 플랫폼에 추가되었습니다.
소개AI 요약
활용 워크플로우
입력
틴포일
출력
Private Inference API
기존 OpenAI SDK 코드에서 Base URL만 변경하여 인클레이브 내 LLM 추론을 즉시 수행합니다.
Tinfoil Containers
임의의 Docker 이미지를 NVIDIA 기밀 컴퓨팅 모드 기반의 격리된 환경에서 실행합니다.
Client-side Verification
브라우저나 SDK에서 서버가 실제 정품 NVIDIA 하드웨어와 Tinfoil 코드인지 직접 검증합니다.
핵심 차별점: NVIDIA H100/B200 하드웨어 수준에서 데이터 물리 격리를 보장하고, 클라이언트가 이를 실시간으로 암호학적으로 검증할 수 있는 세계 유일의 입증 가능한 AI 인프라입니다.
주요 기능AI 요약
- NVIDIA H100·B200 GPU 신뢰 실행 환경(TEE) 기반 기밀 컴퓨팅
- 코드 변경 없는 OpenAI 호환 드롭인 API
- SDK 및 브라우저 기반 하드웨어 원격 증명(Attestation)
- 오픈소스 보안 스택으로 검증 가능한 투명성
- 멀티-GPU 기밀 컴퓨팅 지원 (시장 유일)
장점 & 단점AI 분석
공식 정보와 공개 피드백을 함께 정리한 참고 메모입니다
장점
- NVIDIA 기밀 컴퓨팅 GPU를 기반으로 최고 수준의 프라이버시 제공
- 성능을 희생하지 않고 AI 추론과 학습 가능
- 오픈 소스 소프트웨어 스택으로 완전히 감사 가능
- 암호화로 검증 가능한 솔루션
활용 사례AI 요약
- 민감 데이터와 함께 DeepSeek·Llama 등 대형 모델 사용
- 의료·금융 규제 준수가 필수적인 AI 서비스 구축
- 독점 소스 코드를 사용하는 코파일럿 인프라 보호
- 제로 데이터 리텐션이 필요한 기업용 AI 추론
사용자 리뷰
리뷰를 불러오는 중...
대안 도구
이 도구 대신 사용할 수 있는 대안
클로바 AI
Naver
한국어와 국내 맥락에 최적화된 하이퍼클로바 X로 AI 서비스를 개발·배포하는 통합 플랫폼
애스크코디
코드 생성부터 테스트, 문서화까지 개발 전 과정을 지원하는 멀티 모델 기반 AI 코딩 어시스턴트
컨티뉴
IDE 안에서 원하는 LLM을 선택해 코드 맥락을 제어하는 오픈소스 AI 코딩 어시스턴트
세레브라스
세계 최대 크기의 AI 전용 칩으로 기존 GPU보다 수십 배 빠른 초고속 LLM 추론 환경을 제공하는 API 플랫폼
블랙박스 AI
여러 AI 모델을 골라 쓰고 2억 개 이상의 저장소를 검색하며 실시간 자동완성까지 제공하는 AI 코딩 어시스턴트
그록
자체 LPU 칩으로 오픈소스 모델을 빠르게 돌리는 추론 전용 클라우드 플랫폼입니다. GPU 기반 서비스보다 초당 토큰 생성량이 높고 첫 응답까지의 지연이 짧은 점이 핵심입니다.