
허드
hud
기존 웹 앱과 시스템을 강화학습 환경으로 변환해 AI 에이전트를 훈련하고 평가하는 플랫폼
검증된 사실
- 라이브 가격
- / environment hour · $0.25 2026-06-15 확인
- GitHub
- ★ 15,995
- 최근 변경
- 2026-06-20 HUD(YC W25)와 Y Combinator가 공동 주최하는 강화학습 환경 해커톤(HUD Frontier/RSI RL Environments Hackathon)이 샌프란시스코에서 개최되었으며,
2026-06-15 직접 확인 · 자동 검증 데이터
제품 화면
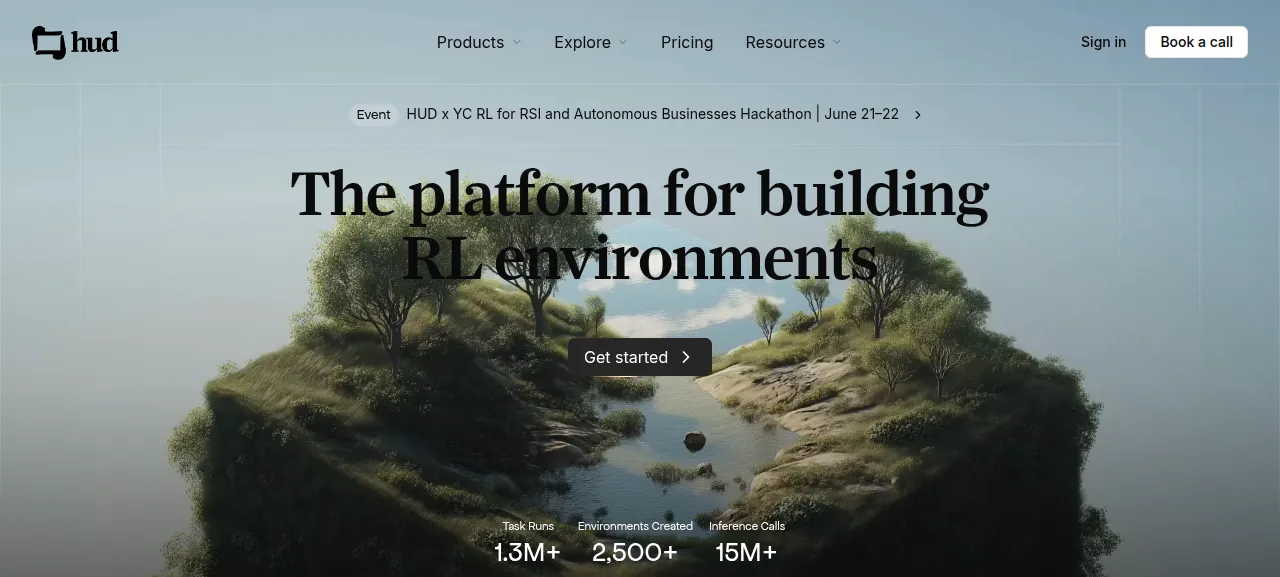
2026-06-15 확인
가격 정보
AI 에이전트 평가 플랫폼으로, 가입 시 $10의 무료 크레딧을 제공하는 프리 티어가 존재한다. SDK 이용은 무료이며, 이후 사용량(Task Run)에 따라 크레딧이 소모되는 구조다. 기업용 플랜은 사용량에 따른 볼륨 프라이싱을 제공한다.
최근 업데이트와 소식
- 성능 측정2026 Autonomy-10 벤치마크 출시 — 9개 도메인 100+ 태스크, 인간 기준선 대비 에이전트 자율성 측정.
2026 Autonomy-10 벤치마크 출시 — 9개 도메인 100+ 태스크, 인간 기준선 대비 에이전트 자율성 측정.
- 소식HUD(YC W25)와 Y Combinator가 공동 주최하는 강화학습 환경 해커톤(HUD Frontier/RSI RL Environments Hackathon)...
HUD(YC W25)와 Y Combinator가 공동 주최하는 강화학습 환경 해커톤(HUD Frontier/RSI RL Environments Hackathon)이 샌프란시스코에서 개최되었으며, 10만 달러 이상의 상금과 컴퓨트 크레딧이 제공되었습니다.
- 버전 업데이트HUD Python SDK 공개 출시 — PyPI를 통해 설치 가능.
HUD Python SDK 공개 출시 — PyPI를 통해 설치 가능.
소개AI 요약
활용 워크플로우
입력
허드
출력
딥 리서치(Deep Research) 경로
Exa 검색 통합을 통해 에이전트가 외부 지식을 탐색하고 요약하는 능력 평가
풀 피처 코딩(Coding) 경로
Language Server 및 Linter가 포함된 IDE 환경에서 코드 생성 및 디버깅 수행
엔터프라이즈 통합 경로
커스텀 웹 프론트엔드와 직접 연결하여 실제 사용자 시나리오 기반 에이전트 훈련
핵심 차별점: 수천 개의 동시 환경을 실시간으로 관리하여 컴퓨터 사용 에이전트(CUA)의 실질적인 신뢰성을 보장하는 고확장성 평가 인프라
주요 기능AI 요약
장점 & 단점AI 분석
공식 정보와 공개 피드백을 함께 정리한 참고 메모입니다
장점
- 원라인 evals와 제로 글루 코드로 벤치마크 테스트 즉시 시작 가능
- 실시간 라이브 트레이스로 에이전트의 클릭·키입력·스크린샷 모니터링 가능
- 1000개 이상 동시 환경을 sub-second 지연시간으로 처리하여 벤치마크 실행 시간 단축
- Claude, GPT-4, Gemini, Grok 등을 단일 API로 멀티모델 테스트 지원
- TLDC 기반 Rubrics로 일반적 LLM 평가 대신 정확한 요구사항 기준 성능 측정 가능
단점
- YC W25 신생 스타트업이라 장기적 레거시 리뷰와 검증이 부족함
- Computer Use Agents 특화라 단순 챗봇 LLM 앱에는 LangSmith 등이 더 적합할 수 있음
- 고품질 RL 환경이 비싸고 폐쇄적이라 오픈소스 생태계 연동 부족 지적 존재
- 기능은 뛰어나나 UI가 다소 일반적이고 에이전트 그래프 시각화가 경쟁사 대비 약함
활용 사례AI 요약
- 웹앱·스프레드시트·내부 도구 대상 에이전트 훈련
- AI 프론티어 랩의 에이전트 강화학습 환경 구축
- 다중 AI 모델 비교 평가 및 선택
- 재무·리서치 분야 자율 AI 에이전트 개발
사용자 리뷰
리뷰를 불러오는 중...
대안 도구
이 도구 대신 사용할 수 있는 대안
허깅페이스
Hugging Face, Inc.
200만 개 이상의 모델과 50만 개 데이터셋을 한곳에 모아두고, Spaces로 데모를 띄우고 Inference API로 추론까지 연결하는 오픈소스 머신러닝 플랫폼
아이닥
의료 영상의 이상 징후를 실시간 탐지하여 응급 환자의 판독 우선순위를 정하고 의료진 협업을 돕는 AI 플랫폼
사이킷런
데이터 전처리부터 다양한 머신러닝 알고리즘 구현까지 직관적인 인터페이스로 지원하는 파이썬 라이브러리
큐벤투스
AI가 수술실 일정과 병상 관리를 자동화하여 병원 운영 효율과 수익성을 극대화하는 플랫폼
비즈AI
CT/MRI 영상 AI 분석으로 뇌졸중·뇌출혈 환자를 즉시 식별하고 치료팀에 자동 알림하는 케어 코디네이션 플랫폼
데이터로봇
기업의 예측 및 생성형 AI 모델 구축부터 배포, 관리까지 전 과정을 자동화하는 통합 엔터프라이즈 플랫폼